Pieces Copilot & Machine Learning
The Pieces Copilot & Machine Learning settings let you configure Copilot chats, manage LLM runtimes, control auto-enrichment, and fine-tune the Long-Term Memory (LTM-2) Engine.
Accessing Settings
To open the Pieces Copilot Chats and Machine Learning configuration screens, click the Settings gear in the bottom-left corner of the Pieces Desktop App’s main view.
Then, navigate to either of the two sections:
-
Copilot Chats: Manage the Pieces Copilot runtime, accent color, LTM defaults, and more.
-
Machine Learning: Configure auto-enrichment and control how Pieces handles cloud vs. local ML processing.
Copilot Chats
Within the Pieces Copilot Chats section, you can adjust your Copilot’s behavior, manage the underlying AI model, and clear chat history as needed.
Manage LLM Runtime
The Manage Copilot LLM Runtime option allows you to switch between available AI models (e.g., “GPT-4o Mini”) or configure any new runtimes provided by Pieces—both cloud and local.
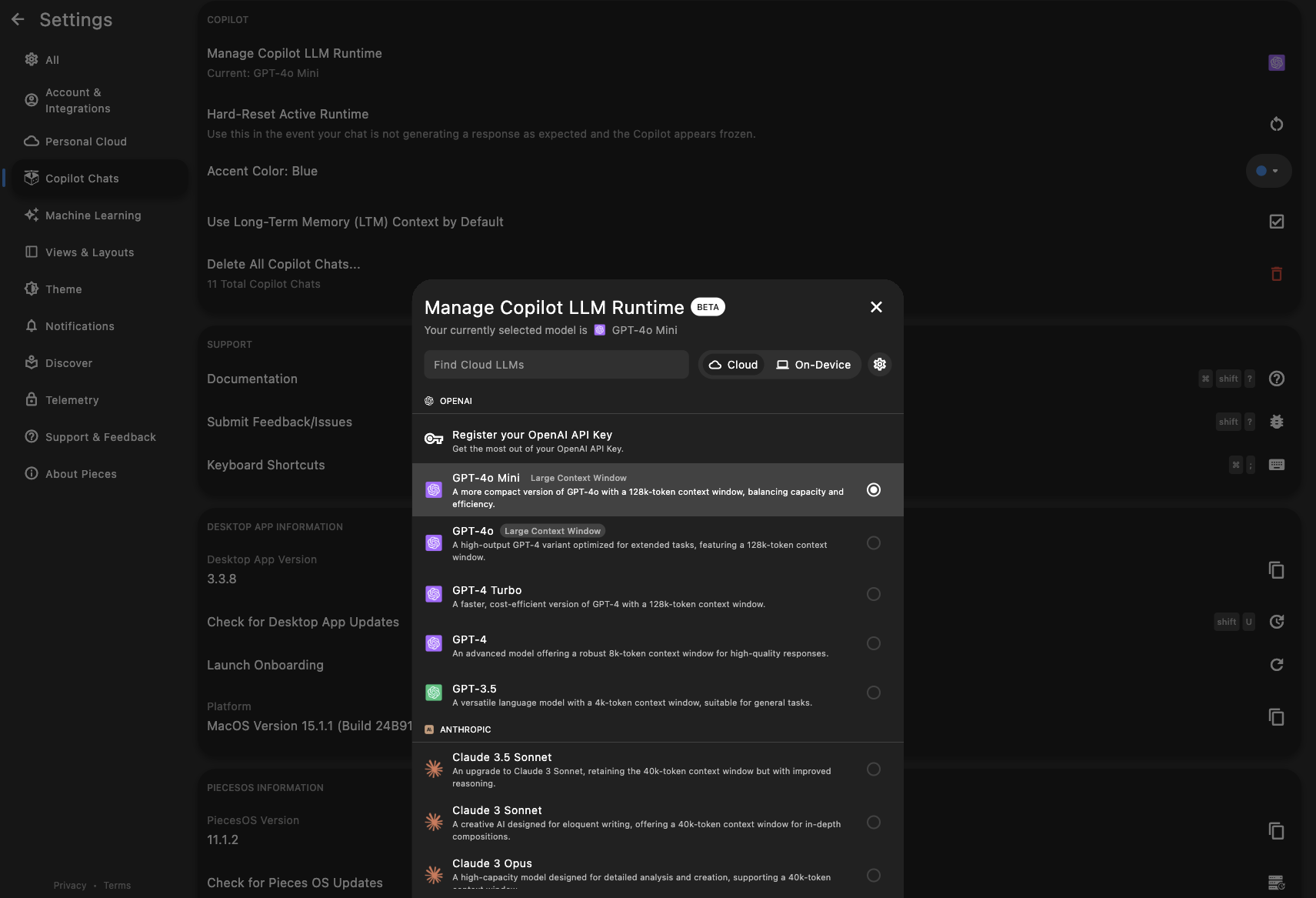
Switching models can be useful if you want to try different levels of quality or speed.
Reset Active Runtime
Use the Hard-Reset Active Runtime button if the Pieces Copilot stops generating responses or behaves unexpectedly.
This effectively restarts the AI model so that it can begin processing requests again.
Accent Color
The Accent Color sets a highlight color for specific elements, like text bubbles and other view-based UI elements within the Pieces Copilot view or other views.
For more information about customizing your UI colors, visit our Aesthetics & Layouts documentation.
Default LTM Behavior
Enable or disable Use Long-Term Memory (LTM-2) Context by Default to control whether Pieces Copilot automatically references your recent workflow context as captured by the LTM.
Turning this off means the AI will respond without leveraging your workflow context unless manually enabled when starting a new Pieces Copilot Chat.
Delete Chats
Click Delete All Copilot Chats to remove all stored chat history from your device.
This is useful if you want to start fresh or clear out older conversations that are no longer needed.
Machine Learning
The Machine Learning section governs how Pieces enriches your saved materials, controls local vs. cloud-based ML resources, and manages on-device LTM.

Auto-Enrichment Behavior
Auto-Enrichment settings let you control how much metadata is automatically attached to code snippets and other saved materials.
Pieces can add tags, related websites, hints, and references to people (e.g., authors of code) at varying levels of detail: No Enriched Data, Low, Medium, and High.
By default, all auto-generated metadata settings are set to Medium.
Lowering these levels may be beneficial if you prefer minimal automatic annotations or need to limit external lookups.
Machine Learning (ML) Processing
Under ML Processing, you can fine-tune how Pieces uses local and cloud resources to power various functions and processes within the Pieces software experience.
Enrichment Mode
You can select whether or not Pieces utilizes cloud or local models—or a mix of both—for saved material enrichment.
-
Blended: Uses both local and cloud resources for material enrichment. -
Local: Restricts enrichment to on-device analysis and generation only—the best case scenario for privacy-forward workflows. -
Cloud: Optimized for speed, Pieces sends your material data to Pieces Cloud for processing.
Selecting the mode that best fits your security and performance needs ensures that Pieces processes your snippets in the most efficient or privacy-conscious way possible.
LTM-2 Engine
Pieces employs an on-device Long-Term Memory (LTM-2) Engine to capture recent contexts, usage patterns, and snippet details for more intelligent Copilot suggestions.
Configurable behaviors include:
-
On: LTM is fully active and enabled by default and on start-up. -
Off: Disables LTM entirely. -
Pause: Provides options for halting the LTM for 15 minutes, 1 hour, 6 hours, 12 hours, or 24 hours.
While paused or off, Pieces Copilot won’t use your workflow context to inform suggestions or provide more accurate information in generative AI responses.
You can read more about the LTM-2 Engine here.
Clearing LTM-2 Data
Click the Trash icon next to Clear Long-Term Memory Engine Data to remove any persisted context that LTM has gathered over time.