Adjusting Pieces Copilot
Customization is key to getting the most out of any AI assistant. Read about switching between local and cloud-hosted models, adjusting the appearance of Pieces Copilot Chats, and more.
Managing the LLM Runtime
There are dozens of local and cloud-hosted LLMs to choose from within the Pieces Desktop App—here’s how to do it.
LLM Runtime Modal
At the bottom left of the Pieces Copilot view is the active model—by default you’ll see GPT4o-Mini.
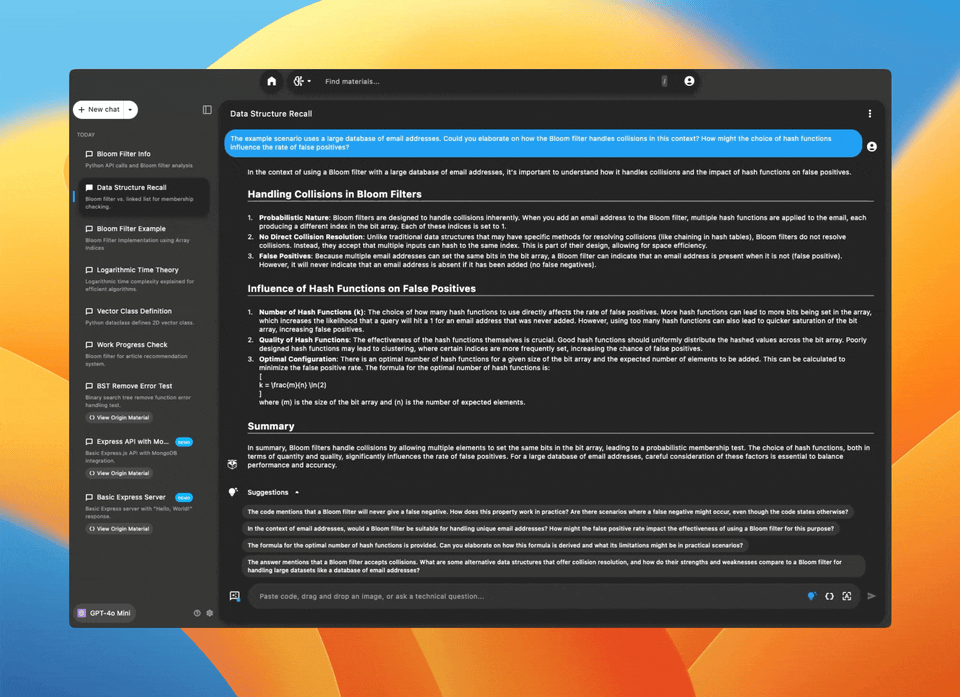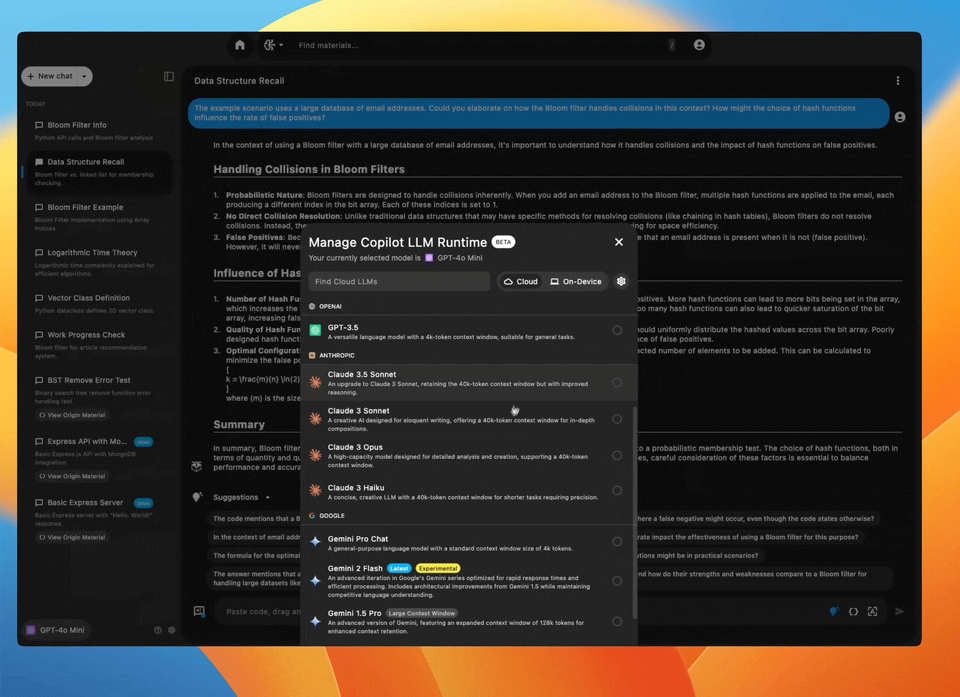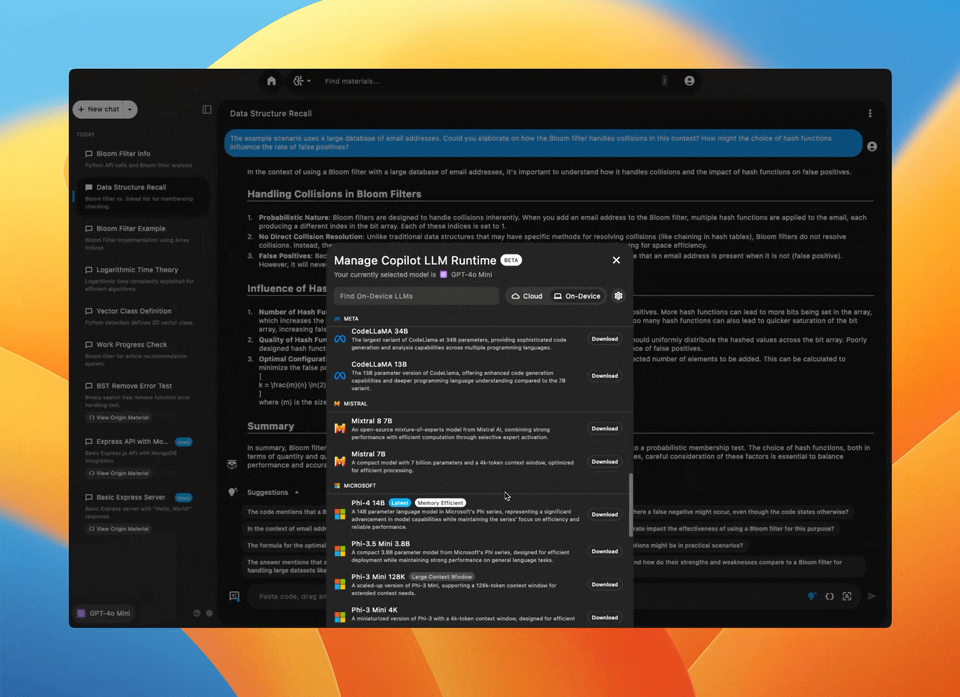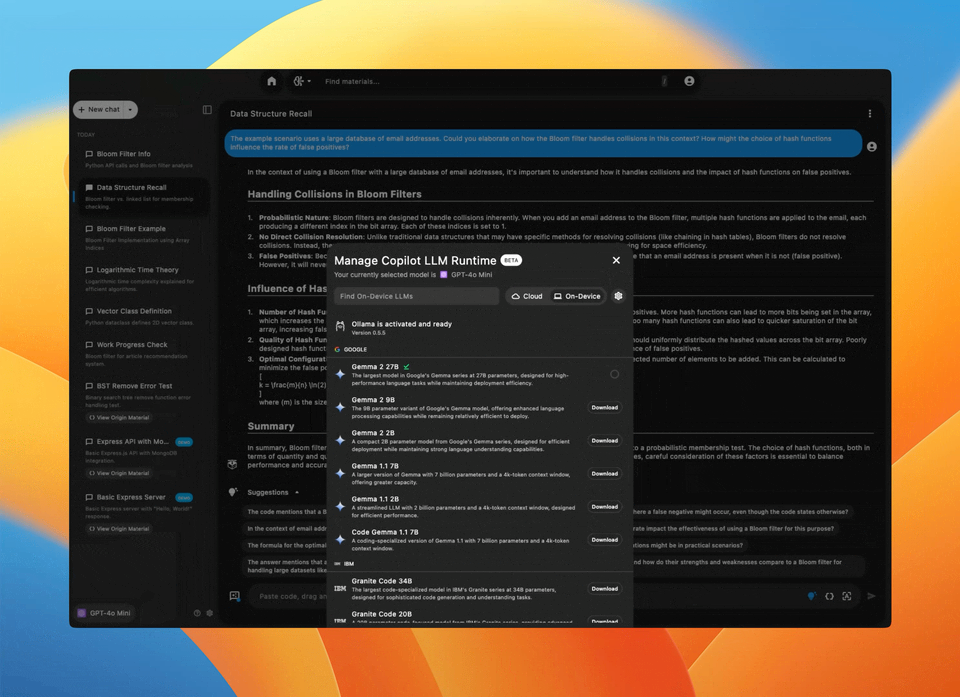
Clicking this button opens the Manage Copilot LLM Runtime modal, where you can enter your own API key or select local and cloud-hosted LLMs served through Pieces.
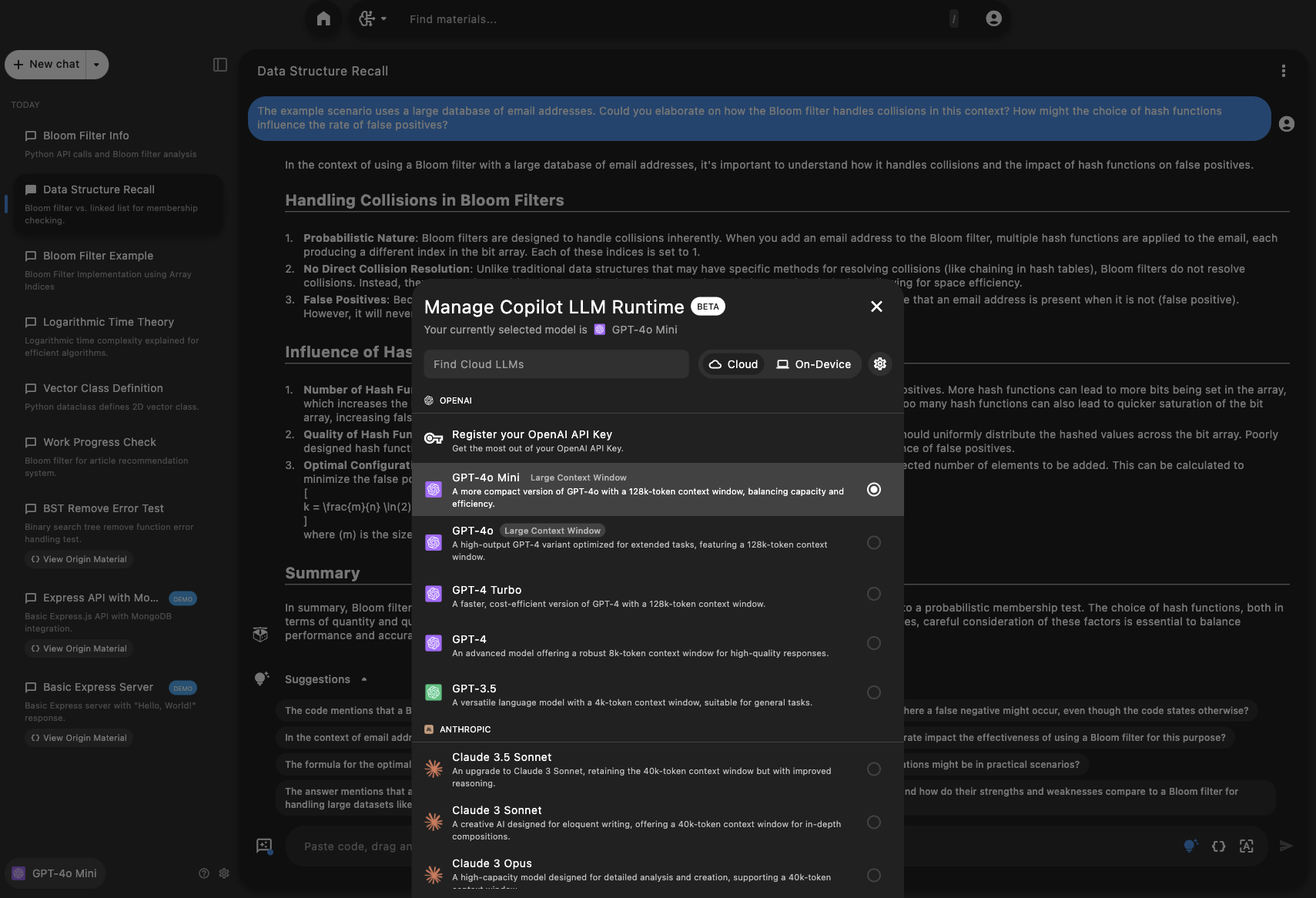
Model Selection
Pieces Copilot allows you to choose between cloud-hosted models and on-device models.
Each option has its benefits:
-
Cloud LLMs: Typically offer state-of-the-art performance and are ideal for complex queries requiring deep context.
-
On-Device LLMs: Ensure data privacy and are optimal for offline or air-gapped environments.
You can read this documentation containing all local and cloud-hosted LLMs served through the Pieces Desktop App.
Resetting Conversations
In case you need a fresh start or want to clear the current context, the interface includes options (accessible via the Chat Options menu) to reset the conversation.
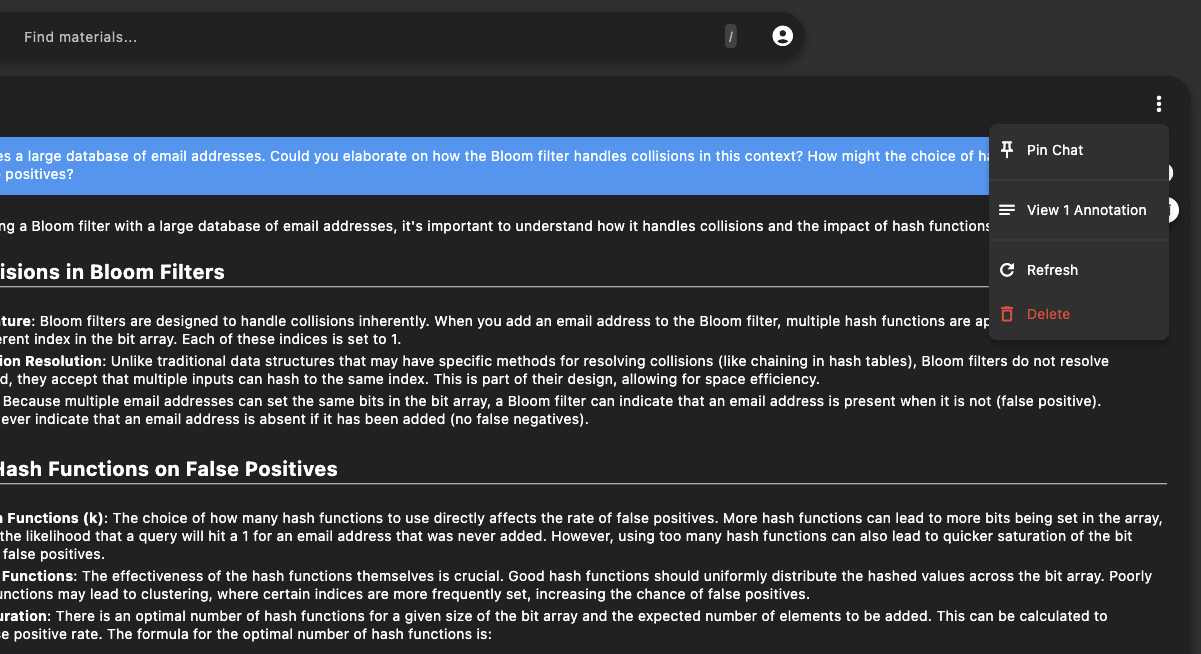
This is particularly useful when you want to switch focus or change the conversation pipeline.
Search Functionality
A search bar labeled Find Cloud LLMs lets you browse available cloud-based models—then, switching to On-Device, you can search through the list of local models available with the optional Ollama client.
Ollama is required to use local LLMs with Pieces software.
If you don’t have it installed, that’s okay—you can download and install it through the Pieces Desktop App by clicking on the Active Model button.
To switch between the Cloud and On-Device model list, click the slider next to the search bar.
Once toggled, the search bar updates to Find On-Device LLMs and shows a message either prompting you to install Ollama or indicating that Ollama is installed and ready, along with its version number.
While Ollama is required for on-device generative AI, you do not need it to use the Long-Term Memory Engine.
This distinction ensures that you can benefit from local Long-Term Memory features even if you choose not to use on-device LLMs.
Adjusting Chat Appearance
Within the same modal area, a Settings Gear icon gives you access to personalization options.
From here, you can choose a chat accent color to customize the look and feel of your Copilot interface, and enable or disable the option to enable LTM by default when starting a new chat.

When enabling Long-Term Memory Context by default, every new chat automatically incorporates your saved long-term memory context, ensuring that your conversations are always informed by your previous work.
You can also use the keyboard shortcut cmd+shift+t (macOS) or ctrl+shift+t (Windows/Linux) to toggle the Dark/Bright theme for the Pieces Desktop App.